Maximum likelihood estimator
STA602 at Duke University
Visualizing the likelihood
\[L(\mu) = f_x(75 |\mu) \cdot f_x(58|\mu) \cdot f_x(68|\mu).\]
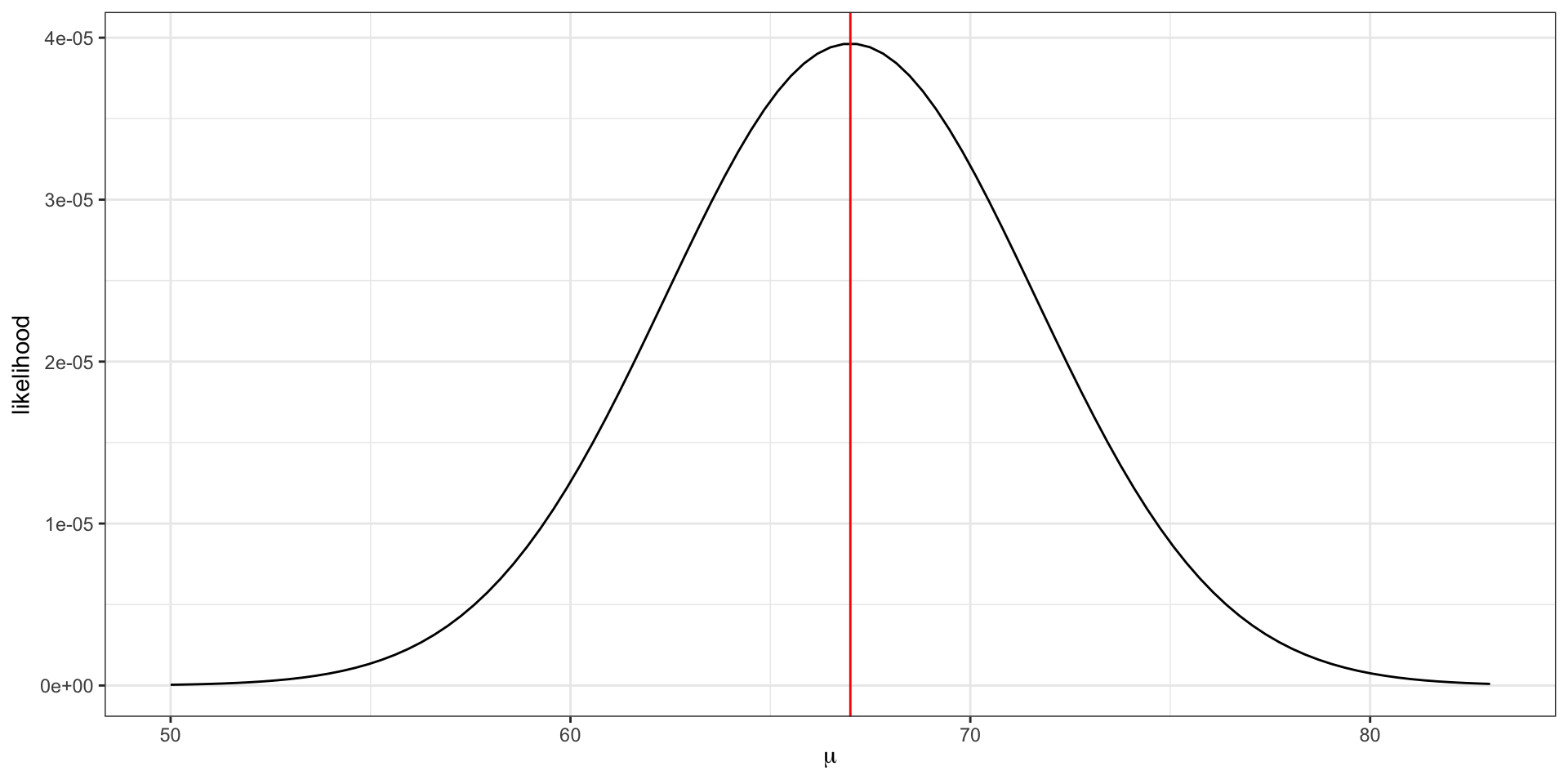
The maximum likelihood estimate \(\hat{\mu} = \frac{75 + 58 + 68}{3} = 67\).
The maximum likelihood estimate is the parameter value that maximizes the likelihood function.