Normal modeling &
Bayesian estimators
STA602 at Duke University
Solution (b)
b
Demo with simulated data to make sure code works:
# simulated data
set.seed(123)
true.theta = 4
true.sigma = 1
N = 10
x = seq(from = 1, to = 10, length = N)
y = rnorm(N, true.theta * x, true.sigma)
# prior parameters
k0 = 1
mu0 = 0
sumYX = sum(y * x)
d = (k0 + sum(x^2))
mun = ((k0 * mu0) + sumYX) / d
tn = sqrt(1 / d)
theta.postsample = rnorm(10000, mun, tn)
hist(theta.postsample)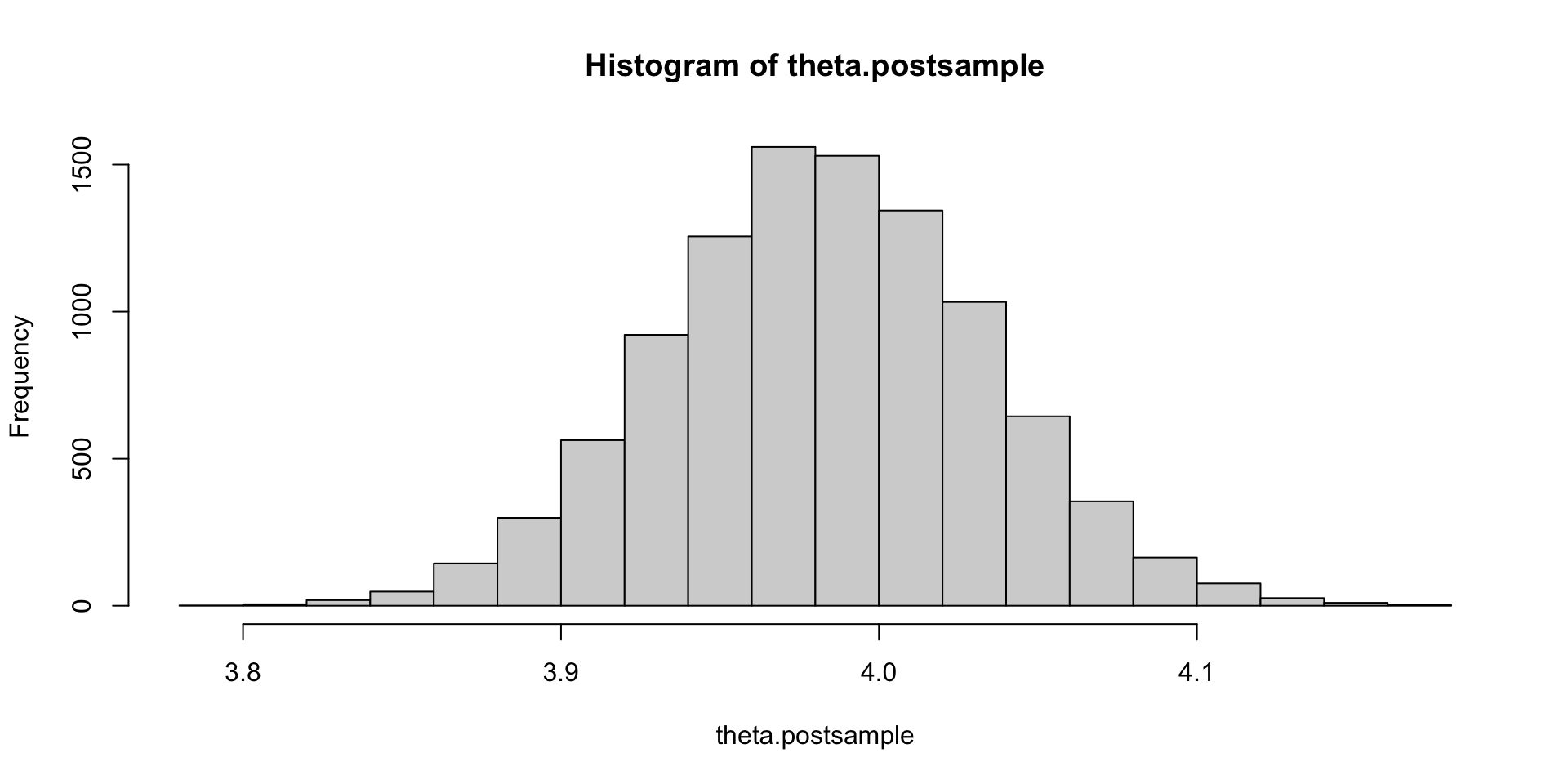

Solution (c)
# use posterior samples of theta and x = 4 to simulate ytilde
ytilde = rnorm(10000, theta.postsample * 4, 1)
hist(ytilde)[1] 3.319342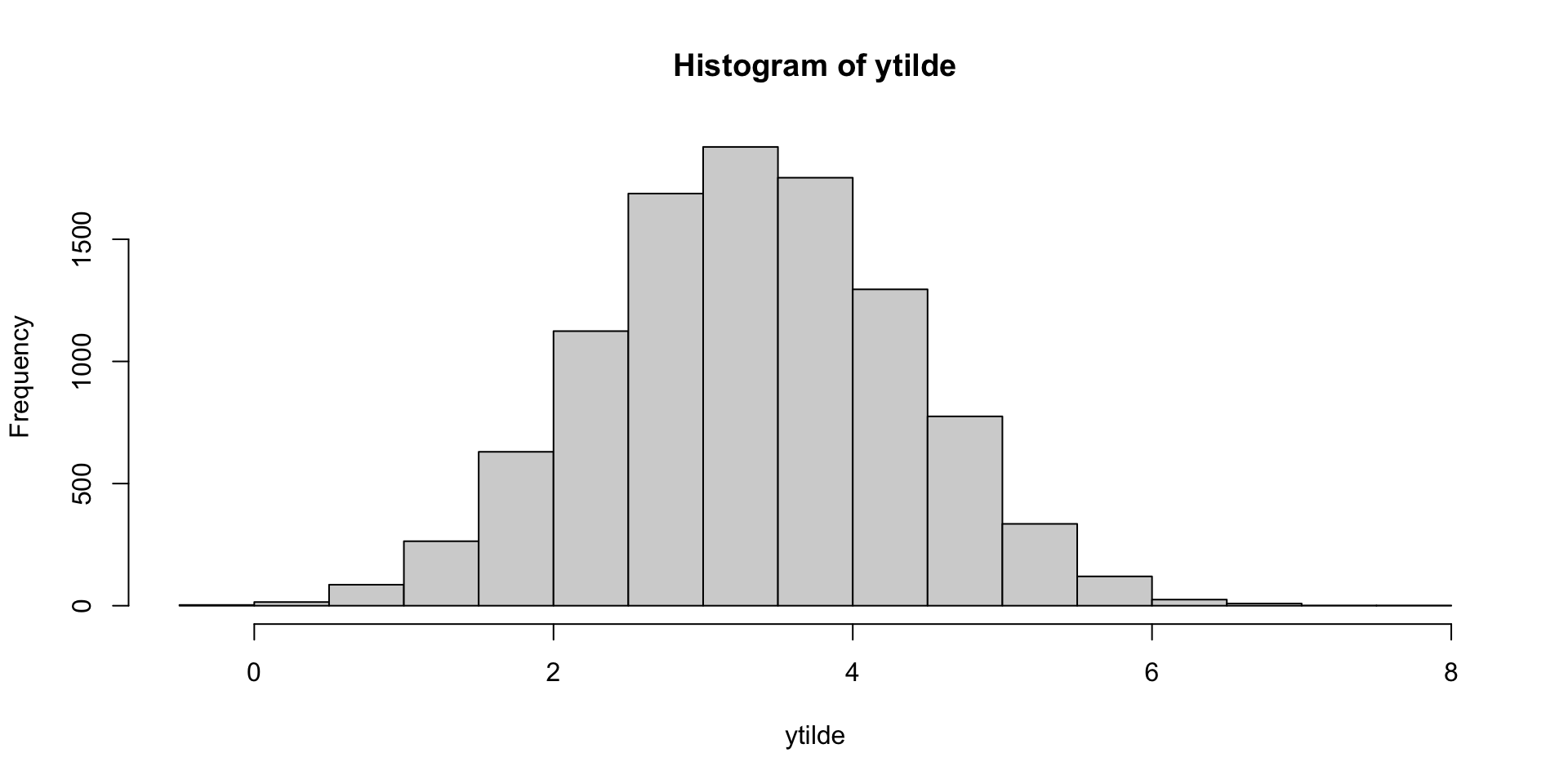
This matches intuition (law of total expectation gives the closed form solution: 4 * 0.838 = 3.352).